Plateforme · Vision
DMS et ADAS complets sur silicium AI-class.
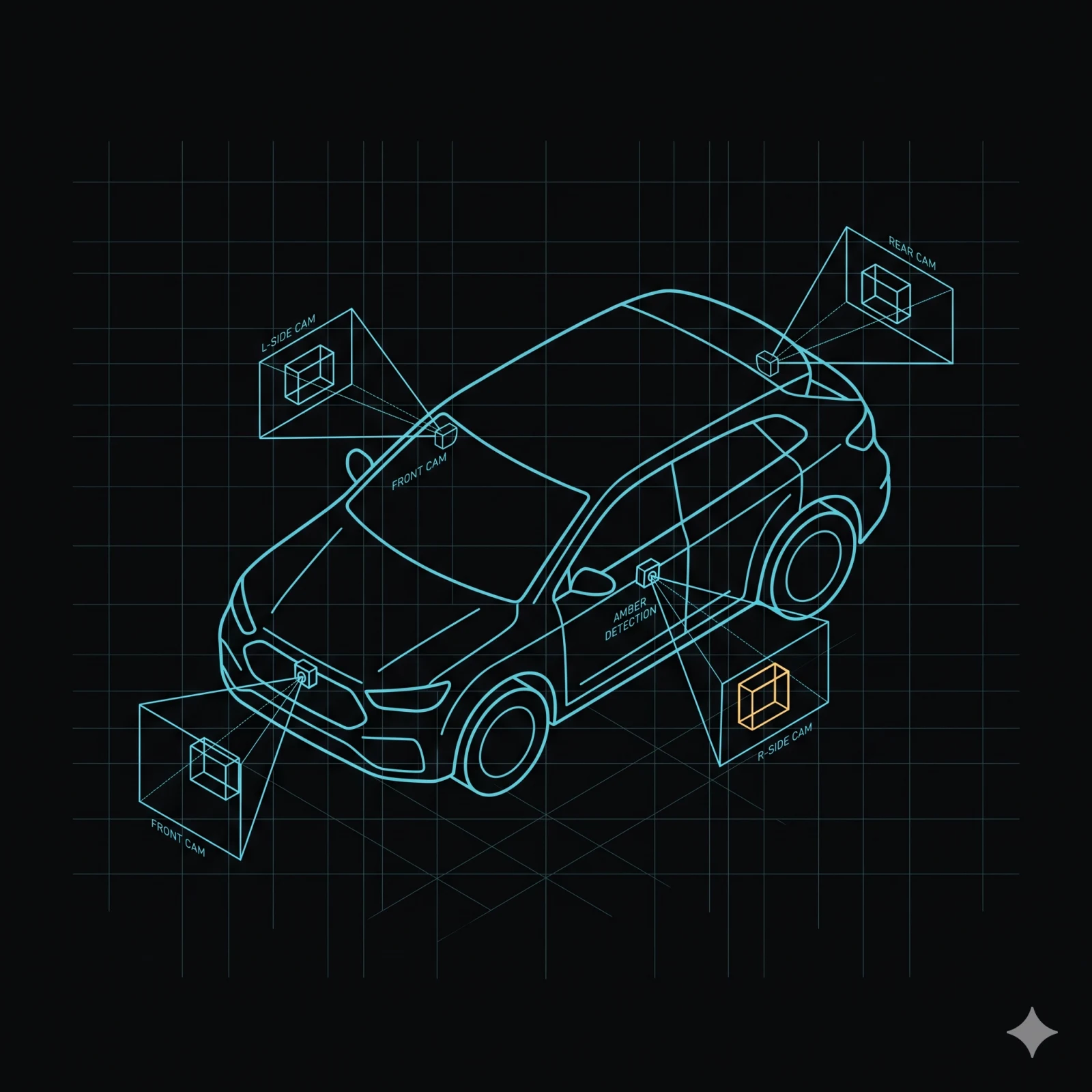
Cinq entrées caméra convergent sur un pipeline en mémoire partagée. La caméra, le GPU et le NPU échangent les frames directement — le CPU ne copie jamais les données pixel. Exécutez cinq modèles en parallèle plus l'encodage H.265 sur un appareil 10-TOPS-class et gardez la marge CPU libre pour votre logique applicative.
MOS4 AI Software Suite
Build, Runtime et Language — trois piliers.
MOS4 AI Software Suite couvre Build (AI Funnel) + Runtime (AI Vision, AI Language). AI Vision est le runtime d'intelligence visuelle — caméra vers NPU sans copies de pixels CPU. AI Language est le runtime d'intelligence textuelle — LLM, RAG et voix sur appareil.
Chiffres clés
Les métriques et invariants de conception.
Capture caméra
Cinq entrées caméra. Une API unifiée.
Cinq entrées caméra convergent sur le même format de frame en mémoire partagée. Les
intégrateurs n'écrivent pas de pipelines spécifiques à chaque plateforme. Parcourez le catalogue de micro services pour explorer
mos-camera-capture, mos-roi-shader et mos-ai-runtime.
Architecture
| Entrée | Backend silicium | Notes |
|---|---|---|
| MIPI-CSI | AI-class / compute-class (direct) | Interface MIPI native ; pas de pont externe |
| GMSL2 | AI-class (framework multimédia fournisseur) | Chemin via pont sérialiseur ; MIPI-CSI direct sur l'autre variante AI-class |
| USB UVC | Les deux | Pilote UVC standard V4L2 |
| Ethernet RTSP/ONVIF | Les deux | Caméras réseau ; streaming RTSP live disponible |
| WebRTC | Les deux | Chemin de streaming compatible navigateur |
Chaque backend normalise sa sortie vers le même format de frame en mémoire GPU partagée avant le tee. Cinq entrées, un contrat d'entrée.
Flux de données caméra vers consommateurs. Le capteur — MIPI-CSI, GMSL2, USB UVC, RTSP/ONVIF, ou WebRTC — produit des frames en mémoire GPU partagée. Le tee ventile ensuite la frame vers trois consommateurs sans copie : le shader ROI GPU pour le recadrage et redimensionnement, l'encodeur dashcam, et le suivi de pose visuel + inertiel. Le shader ROI alimente des handles de tenseurs vers le runtime IA pour l'inférence NPU.
flowchart TD S[Caméra<br/>MIPI-CSI · GMSL2 · UVC · RTSP/ONVIF · WebRTC] S --> G[Mémoire GPU partagée<br/>frame NV12] G --> T[Tee · contrat d'entrée] T --> R[Shader ROI GPU<br/>recadrage et redimensionnement] T --> D[Encodeur dashcam] T --> V[Suivi de pose] R --> A[Runtime IA<br/>inférence NPU] class A ai-node class R ai-node
Échelle + mode dual + usure
Une à huit caméras d'usine
Le runtime supporte nativement une à huit caméras par appareil sur les cinq transports. Des configurations plus larges sont étudiées sur demande.
Enregistrement + stream + upload simultanés
Beaucoup de plateformes caméra forcent à choisir entre enregistrer localement et diffuser ou téléverser d'anciens clips. MOS4 est conçu pour faire les deux à la fois : encodage temps-réel vers le segment sink flash-aware, stream RTSP/WebRTC et upload de clips historiques tournent sur le même plan de frames en mémoire partagée, sans duplication.
Stockage avec wear-leveling
Le segment sink est flash-aware : les écritures sont réparties entre blocs pour étendre l'endurance sur les SKUs premium à exposition longue. Politiques de rétention, clips protégés et file d'upload cloud partagent la même comptabilité d'usure.
Apportez une caméra et un modèle — nous routons les pixels.
Transport de frames
Une frame, plusieurs consommateurs — chacun à son propre rythme.
Une frame produite ; plusieurs consommateurs s'abonnent à des cadences indépendantes. Les consommateurs lents ne bloquent jamais le producteur ; les frames perdues sont comptabilisées par sujet.
jusqu'à 60 Hz
Vidéo
Frames en débit plein vers l'encodeur dashcam ou tout abonné — plafonné à 60 Hz. Voir les cas d'usage vidéo.
30 Hz
Recadrage et redimensionnement GPU
Extraction ROI au rythme d'inférence NPU.
10 Hz
Suivi de pose
Le suivi de pose visuel + inertiel s'abonne à sa propre cadence — chaque abonné est indépendant.
Détection en deux étapes
Analyser toute la frame rapidement, puis rexaminer les parties qui comptent.
Le triage détecte sur la frame complète ; les modèles raffinés rexaminent ensuite uniquement les régions d'intérêt. La boucle de métadonnées entre le runtime IA et le recadrage GPU porte des boîtes englobantes et un identifiant de modèle — quelques dizaines d'octets par détection, aucune donnée pixel ne traverse le bus entre les étapes.
Détection en deux étapes. La caméra publie la frame complète vers le runtime IA, qui exécute l'inférence de triage et produit des boîtes englobantes de détection avec des labels de classe et des scores de confiance. Le runtime envoie ensuite des métadonnées de boîtes englobantes et un identifiant de modèle — quelques dizaines d'octets, aucune donnée pixel — vers le shader ROI GPU. Le shader recadre, redimensionne et normalise chaque région et retourne un handle tenseur par ROI. Le runtime exécute ensuite l'inférence raffinée par ROI.
sequenceDiagram participant Cam as Caméra participant Ai as Runtime IA participant Roi as Shader ROI GPU Cam->>Ai: frame partagée — image complète Note over Ai: inférence de triage<br/>détection bbox + classe + confiance Ai->>Roi: SelectRois(bbox[], model_id) — quelques dizaines d'octets Note over Roi: recadrage + redimensionnement + normalisation GPU par ROI Roi-->>Ai: handle tenseur par ROI (1:N) Note over Ai: inférence raffinée par ROI
Recadrage et redimensionnement GPU
Même config, même interface — quelle que soit la famille de silicium.
Le shader ROI GPU exécute le recadrage, le redimensionnement et la normalisation entièrement sur le GPU. Le framework s'adapte au matériel en interne — les intégrateurs voient une seule configuration et une seule interface quelle que soit la famille de silicium. La boucle de métadonnées ne porte que la boîte englobante et l'identifiant de modèle — pas de pixels.
Architecture · par famille de silicium
AI-class — variante MIPI-CSI
Shader ROI GPU portable. Inférence NPU via le délégué du fournisseur de silicium. La mémoire partagée GPU-vers-NPU directe n'est pas disponible sur cette variante ; le tenseur de sortie GPU est transmis au NPU comme tenseur standard.
AI-class — variante pont sérialiseur
Shader ROI GPU portable, plus mémoire partagée GPU-vers-NPU pour réutiliser le tenseur sans réimportation. Prend en charge jusqu'à ~100 TOPS sur le palier AI-class.
Voir le matériel pris en charge pour les détails des paliers de silicium et les facteurs de forme.
Inférence NPU
Runtime IA : charger les modèles par chemin ou octets.
Charger plusieurs modèles, les exécuter en parallèle, déployer ONNX ou TFLite directement. La réentrance sur le même modèle est empêchée par construction.
Surface API
| Méthode | Description |
|---|---|
| LoadModel | Charger un modèle .tflite par chemin ou octets |
| UnloadModel | Libérer un modèle et ses ressources NPU |
| RunInference | Accepte une frame en mémoire GPU partagée en entrée ; retourne les tenseurs de détection |
| ListModels | Énumérer les modèles chargés avec leurs métadonnées |
Plusieurs modèles chargent et s'exécutent en parallèle ; la réentrance sur le même modèle est impossible par construction. L'entrée est exclusivement la frame en mémoire GPU partagée — aucun chemin de copie pixel CPU n'existe dans le code de production. Les modèles ONNX peuvent être auto-convertis avant le déploiement.
Pour le moteur de pipeline IA, l'ordonnancement DAG et l'intégration Cloud Connect, voir AI Funnel.
Suivi de pose visuel + inertiel
Visuel + inertiel + GNSS, fusionnés sur le device.
Placement futur : Le contenu de l'odométrie visuelle et inertielle sera déplacé vers une page dédiée /platform/robotics dans une version future. En attendant la création de cette page, ce contenu reste ici.
Le suivi de pose fusionne caméra, inertiel et GNSS. L'absence de GNSS en intérieur déclenche un soft-fail gracieux ; la persistance de carte survit aux redémarrages.
Le chiffre ≤33 ms par frame provient d'un harnais synthétique de 300 frames — pas d'un benchmark validé sur cible réelle. Le timing sur cible réelle est en attente. Présentez la fonctionnalité en conséquence.
Architecture
Le front-end visuel extrait des coins, calcule des descripteurs binaires et amorce le tracking avec un rejet robuste des valeurs aberrantes. Les données inertielles sont pré-intégrées avec covariance complète ; la fusion GNSS s'exécute via un optimiseur par graphe de facteurs. Aucune dépendance externe de bibliothèque SLAM.
| Méthode | Description |
|---|---|
| StreamPose | Pose 6-DOF avec covariance — fusion visuelle seule ou visuelle + inertielle |
| GetStatus | État de santé actuel du suivi de pose et état de tracking |
| GetMapStats | Nombre de points de repère, images clés, fermetures de boucle |
| SaveMap | Persister la carte courante pour survivre à un redémarrage |
| LoadMap | Restaurer une carte sauvegardée pour démarrer le tracking |
La persistance de carte survit aux redémarrages via une écriture atomique de fichier.
Anonymisation RGPD
Anonymisation en direct, avant que toute frame ne quitte le pipeline.
Une étape d'anonymisation optionnelle s'exécute dans le pipeline de capture — avant l'encodeur dashcam et avant tout consommateur en aval. Les services en aval reçoivent des frames déjà anonymisées sans étape d'intégration supplémentaire.
Ce qui est anonymisé
Les visages et plaques d'immatriculation sont pixélisés dans le pipeline. Aucune donnée biométrique brute n'atteint l'encodeur ni aucun service en aval.
Placement dans le pipeline
L'étape d'anonymisation se place avant l'encodeur dashcam et avant tous les autres consommateurs de frames. Il n'y a pas d'étape de post-traitement ni besoin de coordonner entre les services.
Politique au démarrage
Activée ou désactivée via un indicateur de configuration au démarrage. Le basculement en direct sans redémarrage n'est pas pris en charge — le pipeline est reconstruit au démarrage. Cela rend l'application des politiques auditable et déterministe.
Intégration dashcam
L'encodeur dashcam reçoit des frames déjà anonymisées. Aucune étape d'intégration supplémentaire n'est requise. La même frame déjà anonymisée atteint tous les autres abonnés du pipeline.
Observabilité
14 métriques intégrées dans le pipeline.
Shader ROI GPU — 6 métriques
Appels, ROI extraits, histogramme de durée et 3 autres. S'intègre au pipeline d'observabilité MOS4 sans code d'instrumentation par service.
Runtime IA — 8 métriques
Compteurs, histogrammes et une jauge — dont un watchdog d'activité d'inférence avec un budget de 5 s. Même intégration sans instrumentation.
FAQ
Questions fréquentes
-
Quelles entrées caméra sont prises en charge ?
Cinq : MIPI-CSI (direct sur silicium AI-class / compute-class), GMSL2 (chemin pont sérialiseur AI-class), USB UVC, Ethernet RTSP/ONVIF, et WebRTC. Les chemins de streaming RTSP live et WebRTC sont tous deux disponibles.
-
Le CPU touche-t-il jamais les données pixel ?
Non, par conception. La caméra, le GPU et le NPU échangent la même frame en mémoire partagée via des handles. Le mappage pixel CPU est une violation de spec dans les builds de production.
-
Puis-je exécuter plusieurs modèles IA en parallèle avec l'encodage vidéo ?
Oui. Le pipeline est dimensionné pour exécuter une charge DMS + ADAS complète (5 modèles) plus l'encodage H.265 sur un appareil 10-TOPS-class avec la marge CPU libre pour la logique applicative.
-
Comment l'anonymisation RGPD s'intègre-t-elle ?
Une étape d'anonymisation optionnelle pixélise les visages et les plaques d'immatriculation avant que les frames n'atteignent l'encodeur dashcam ou tout consommateur en aval. L'activation ou la désactivation nécessite un redémarrage. Les consommateurs en aval reçoivent des frames déjà anonymisées sans étape d'intégration supplémentaire.
-
Que signifie le chiffre de timing du suivi de pose ?
Le chiffre ≤33 ms par frame provient d'un harnais synthétique de 300 frames, pas d'un benchmark validé sur cible réelle. Le benchmarking sur cible réelle est en cours. Le pipeline cible 30 FPS.
FAQ architecture
Détails d'implémentation
-
Comment l'extraction ROI fonctionne-t-elle selon les familles de silicium ?
Le shader ROI GPU importe la frame en mémoire GPU partagée, exécute letterbox + conversion de format sur le GPU, et produit un handle tenseur par ROI. Le shader est portable sur les deux variantes de silicium AI-class. Une variante AI-class supporte en plus la mémoire partagée GPU-vers-NPU directe afin que le NPU réutilise le tenseur sans réimportation — ce chemin est spécifique au silicium.
-
À quoi ressemble le pipeline de suivi de pose en interne ?
Le front-end visuel extrait des coins, calcule des descripteurs binaires et amorce le tracking avec un rejet robuste des valeurs aberrantes. Les données inertielles sont pré-intégrées avec covariance complète et fusionnées avec le GNSS via un optimiseur par graphe de facteurs. Aucune dépendance externe de bibliothèque SLAM — le pipeline complet est écrit en Rust.
Apportez une caméra et un cas d'usage.
Une démo live sur du matériel Munic — votre bureau, votre véhicule ou votre machine. Parlez à l'équipe technique pour adapter le palier SoC à votre budget de latence et de calcul.