Plataforma · Visión
DMS y ADAS completo en silicon AI-class.
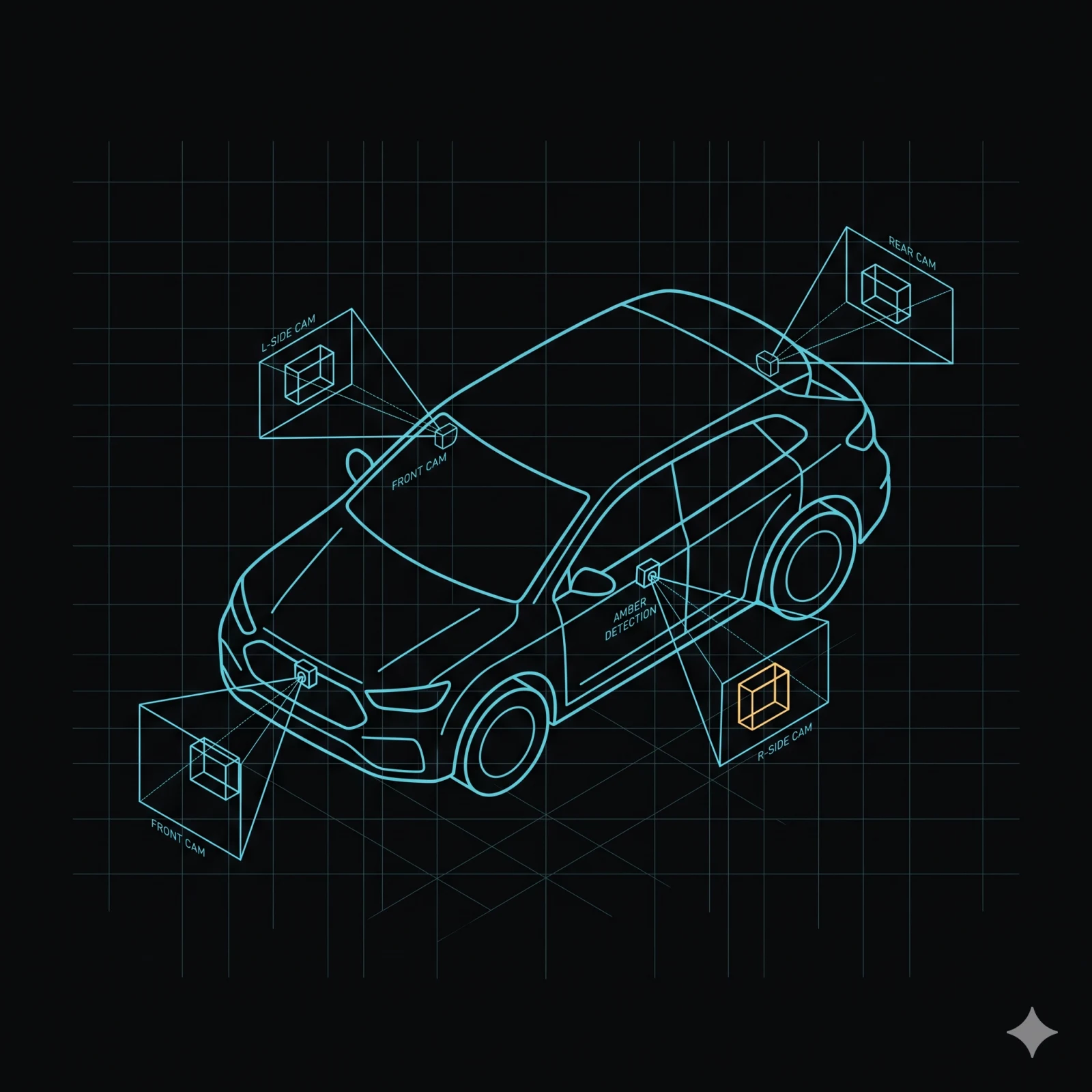
Cinco entradas de cámara convergen en un pipeline de memoria compartida. Cámara, GPU y NPU intercambian frames directamente — la CPU nunca copia datos de píxeles. Ejecute cinco modelos concurrentes más codificación H.265 en un dispositivo de clase 10 TOPS y conserve margen de CPU libre para su lógica de aplicación.
MOS4 AI Software Suite
Build, Runtime y Language — tres pilares.
MOS4 AI Software Suite cubre Build (AI Funnel) + Runtime (AI Vision, AI Language). AI Vision es el runtime de inteligencia visual — cámara a NPU sin copias de píxeles en CPU. AI Language es el runtime de inteligencia textual — LLM, RAG y voz en el dispositivo.
Indicadores clave
Los números e invariantes de diseño.
Captura de cámara
Cinco entradas de cámara. Una API unificada.
Cinco entradas de cámara convergen en el mismo formato de frame en memoria compartida. Los
integradores no escriben pipelines por plataforma. Explore el catálogo de micro services
para descubrir mos-camera-capture, mos-roi-shader y mos-ai-runtime.
Arquitectura
| Entrada | Backend de silicon | Notas |
|---|---|---|
| MIPI-CSI | Clase AI / clase compute (directo) | Interfaz MIPI nativa; sin puente externo |
| GMSL2 | Clase AI (framework multimedia del proveedor) | Ruta por puente serializador; MIPI-CSI directo en la otra variante de clase AI |
| USB UVC | Ambas | Driver de clase V4L2 UVC estándar |
| Ethernet RTSP/ONVIF | Ambas | Cámaras de red; streaming RTSP en vivo disponible |
| WebRTC | Ambas | Ruta de streaming en vivo compatible con navegador |
Cada backend normaliza la salida al mismo formato de frame en memoria GPU compartida antes del tee. Cinco entradas, un contrato de entrada.
Flujo de datos de cámara a consumidores. El sensor — MIPI-CSI, GMSL2, USB UVC, RTSP/ONVIF o WebRTC — produce frames en memoria GPU compartida. El tee distribuye el frame a tres consumidores sin copiarlo: el shader ROI GPU para recorte y reescalado, el codificador dashcam y el rastreador de pose visual + inercial. El shader ROI alimenta handles de tensor al runtime AI para inferencia NPU.
flowchart TD S[Cámara<br/>MIPI-CSI · GMSL2 · UVC · RTSP/ONVIF · WebRTC] S --> G[Memoria GPU compartida<br/>Frame NV12] G --> T[Tee · contrato de entrada] T --> R[Shader ROI GPU<br/>recorte y reescalado] T --> D[Codificador dashcam] T --> V[Rastreador de pose] R --> A[Runtime AI<br/>Inferencia NPU] class A ai-node class R ai-node
Escala + modo dual + desgaste
De una a ocho cámaras de fábrica
El runtime soporta de forma nativa de una a ocho cámaras por dispositivo en los cinco transportes. Configuraciones mayores se estudian a petición.
Grabar + emitir + subir a la vez
Muchas plataformas de cámara obligan a elegir entre grabar en local y emitir o subir clips antiguos. MOS4 está diseñado para ambas cosas a la vez: codificación en vivo al segment sink flash-aware, stream RTSP/WebRTC y subida de clips históricos corren sobre el mismo plano de frames en memoria compartida, sin duplicar buffers.
Almacenamiento con wear-leveling
El segment sink es flash-aware: las escrituras se reparten entre bloques para alargar la resistencia en SKUs premium de exposición larga. Las políticas de retención, los clips protegidos y la cola de subida a la nube comparten la misma contabilidad de desgaste.
Trae una cámara y un modelo — nosotros enrutamos los píxeles.
Transporte de frames
Un frame, muchos consumidores — cada uno a su propio ritmo.
Un frame producido; muchos consumidores se suscriben a cadencias independientes. Los consumidores lentos nunca bloquean al productor; los frames descartados se rastrean por tema.
hasta 60 Hz
Video
Frames a plena frecuencia para el codificador dashcam o cualquier suscriptor — limitado a 60 Hz. Ver casos de uso de video.
30 Hz
Recorte y reescalado en GPU
Extracción de ROI a la frecuencia de inferencia NPU.
10 Hz
Seguimiento de pose
El rastreador de pose visual + inercial se suscribe a su propia cadencia — cada suscriptor es independiente.
Detección en dos etapas
Escanee el frame completo rápido, luego revise las partes que importan.
La clasificación detecta en el frame completo; los modelos refinados luego revisan solo las regiones de interés. El bucle de metadatos entre el runtime AI y el recorte GPU lleva bounding boxes y un ID de modelo — decenas de bytes por detección, sin datos de píxeles cruzando el bus entre etapas.
Detección en dos etapas. La cámara publica el frame completo al runtime AI, que ejecuta inferencia de clasificación y produce bounding boxes de detección con etiquetas de clase y puntuaciones de confianza. El runtime luego envía metadatos de bounding box y un ID de modelo — decenas de bytes, sin datos de píxeles — al shader ROI GPU. El shader recorta, reescala y normaliza cada región y devuelve un handle de tensor por ROI. El runtime entonces ejecuta la inferencia refinada por ROI.
sequenceDiagram participant Cam as Cámara participant Ai as Runtime AI participant Roi as Shader ROI GPU Cam->>Ai: frame compartido — imagen completa Note over Ai: inferencia de clasificación<br/>detectar bbox + clase + confianza Ai->>Roi: SelectRois(bbox[], model_id) — decenas de bytes Note over Roi: recorte + reescalado + normalización por ROI en GPU Roi-->>Ai: handle de tensor por ROI (1:N) Note over Ai: inferencia refinada por ROI
Recorte y reescalado en GPU
Misma configuración, misma interfaz — en todas las familias de silicon.
El shader ROI GPU ejecuta recorte, reescalado y normalización íntegramente en la GPU. El framework se adapta al hardware internamente — los integradores ven una configuración y una interfaz en todas las familias de silicon. El bucle de metadatos lleva solo bounding box y ID de modelo — sin píxeles.
Arquitectura · por familia de silicon
Clase AI — variante MIPI-CSI
ROI GPU portable. Inferencia NPU mediante el delegado del proveedor de silicon. La memoria compartida GPU-a-NPU directa no está disponible en esta variante; el tensor de salida de GPU se entrega a la NPU como tensor estándar.
Clase AI — variante con puente serializador
ROI GPU portable, más memoria compartida GPU-a-NPU para reutilización de tensores sin reimportación. Admite hasta ~100 TOPS en el nivel de clase AI.
Consulte hardware compatible para detalles de niveles de silicon y factores de forma.
Inferencia NPU
Runtime AI: cargue modelos por ruta o bytes.
Cargue múltiples modelos, ejecútelos de forma concurrente, despliegue ONNX o TFLite directamente. La reentrada del mismo modelo está impedida por construcción.
Superficie de API
| Método | Descripción |
|---|---|
| LoadModel | Cargar un modelo .tflite por ruta o bytes |
| UnloadModel | Liberar un modelo y sus recursos NPU |
| RunInference | Acepta un frame en memoria GPU compartida como entrada; devuelve tensores de detección |
| ListModels | Enumerar modelos cargados con metadatos |
Múltiples modelos se cargan y ejecutan de forma concurrente; la reentrada del mismo modelo es imposible por construcción. La entrada es exclusivamente el frame en memoria GPU compartida — no existe ruta de copia de píxeles en CPU en el código de producción. Los modelos ONNX pueden autoconvertirse antes del despliegue.
Para el motor de pipeline AI, la planificación DAG y la integración con Cloud Connect, consulte AI Funnel.
Seguimiento de pose visual + inercial
Visual + inercial + GNSS, fusionado en el dispositivo.
Ubicación futura: El contenido de odometría visual e inercial se trasladará a una página dedicada /platform/robotics en una versión futura. Hasta que esa página exista, este contenido permanece aquí.
El seguimiento de pose fusiona cámara, datos inerciales y GNSS. La ausencia de GNSS en interiores activa un fallo suave elegante; la persistencia del mapa sobrevive a reinicios.
La cifra de ≤33 ms por frame proviene de un arnés sintético de 300 frames — no de un benchmark validado en hardware real. El tiempo en hardware real está pendiente. Presente la característica en consecuencia.
Arquitectura
El front-end visual extrae características de esquinas, calcula descriptores binarios y arranca el seguimiento con rechazo robusto de valores atípicos. Los datos inerciales se preintegran con covarianza completa; la fusión GNSS se ejecuta mediante un optimizador de grafo de factores. Sin dependencias de librería SLAM externa.
| Método | Descripción |
|---|---|
| StreamPose | Pose 6-DOF con covarianza — fusión solo visual o visual-inercial |
| GetStatus | Estado actual del rastreador de pose y estado de seguimiento |
| GetMapStats | Conteo de landmarks, keyframes y cierres de bucle |
| SaveMap | Persistir el mapa actual para sobrevivir un reinicio |
| LoadMap | Restaurar un mapa guardado para arrancar el seguimiento |
La persistencia del mapa sobrevive a reinicios mediante escritura atómica de archivo.
Anonimización GDPR
Anonimización en vivo, antes de que cualquier frame salga del pipeline.
Una etapa de anonimización opcional se ejecuta en el pipeline de captura — antes del codificador dashcam y antes de cualquier consumidor posterior. Los servicios posteriores reciben frames ya anonimizados sin ningún paso de integración adicional.
Qué se anonimiza
Las caras y matrículas se pixelizan en el pipeline. Ningún dato biométrico bruto llega al codificador ni a ningún servicio posterior.
Ubicación en el pipeline
La etapa de anonimización se sitúa antes del codificador dashcam y antes de todos los demás consumidores de frames. No hay paso de postprocesamiento ni necesidad de coordinación entre servicios.
Política en tiempo de arranque
Se activa o desactiva mediante una bandera de configuración en tiempo de arranque. El cambio en caliente sin reinicio no está soportado — el pipeline se reconstruye al inicio. Esto mantiene el cumplimiento de la política auditable y determinista.
Integración con dashcam
El codificador dashcam recibe frames que ya están anonimizados. No se requiere ningún paso de integración adicional. El mismo frame ya anonimizado llega a cada otro suscriptor del pipeline.
Observabilidad
14 métricas incorporadas en el pipeline.
Shader ROI GPU — 6 métricas
Llamadas, ROIs extraídas, histograma de duración y 3 más. Se integra con el pipeline de observabilidad de MOS4 sin código de instrumentación por servicio.
Runtime AI — 8 métricas
Contadores, histogramas y un gauge — incluyendo un watchdog de heartbeat de inferencia con un presupuesto de 5 s. Misma integración de cero instrumentación.
Preguntas frecuentes
Preguntas habituales
-
¿Qué entradas de cámara son compatibles?
Cinco: MIPI-CSI (directo en silicon de clase AI / clase compute), GMSL2 (ruta por puente serializador de clase AI), USB UVC, Ethernet RTSP/ONVIF y WebRTC. Las rutas de streaming RTSP y WebRTC en vivo están disponibles.
-
¿La CPU toca alguna vez los datos de píxeles?
No, por diseño. La cámara, la GPU y la NPU intercambian el mismo frame en memoria compartida mediante paso de handles. El mapeo de píxeles en CPU es una violación de especificación en las compilaciones de producción.
-
¿Puedo ejecutar varios modelos de AI de forma simultánea junto con la codificación de video?
Sí. El pipeline está dimensionado para ejecutar una carga de trabajo DMS + ADAS completa (5 modelos) más codificación H.265 en un dispositivo de clase 10 TOPS manteniendo margen de CPU libre para la lógica de aplicación.
-
¿Cómo se integra la anonimización GDPR?
Una etapa de anonimización opcional pixeliza caras y matrículas antes de que los frames lleguen al codificador dashcam o a cualquier consumidor posterior. Activarla o desactivarla requiere un reinicio. Los consumidores posteriores reciben frames ya anonimizados sin ningún paso de integración adicional.
-
¿Qué significa la cifra de temporización del seguimiento de pose?
La cifra de ≤33 ms por frame proviene de un arnés sintético de 300 frames, no de un benchmark validado en hardware real. El benchmark en hardware real está en curso. El pipeline apunta a 30 FPS.
Preguntas de arquitectura
Detalles de implementación
-
¿Cómo funciona la extracción de ROI entre familias de silicon?
El shader ROI GPU importa el frame en memoria GPU compartida, ejecuta letterbox y conversión de formato en la GPU, y genera un handle de tensor por ROI. El shader es portable entre ambas variantes de silicon de clase AI. Una variante de clase AI admite además memoria compartida GPU-a-NPU directa para que la NPU reutilice el tensor sin reimportación — esa ruta es específica del silicon.
-
¿Cómo es internamente el pipeline de seguimiento de pose?
El front-end visual extrae características de esquinas, calcula descriptores binarios y arranca el seguimiento con rechazo robusto de valores atípicos. Los datos inerciales se preintegran con covarianza completa y se fusionan con GNSS mediante un optimizador de grafo de factores. Sin dependencias de librería SLAM externa — el pipeline completo está escrito en Rust.
Traiga una cámara y un caso de uso.
Una demo en vivo en hardware de Munic — su oficina, su vehículo o su máquina. Hable con ingeniería para emparejar el nivel de SoC con su presupuesto de latencia y cómputo.