Plattform · Vision
Vollständiges DMS und ADAS auf AI-class-Silizium.
Fünf Kamera-Eingaben konvergieren auf einer Shared-Memory-Pipeline. Kamera, GPU und NPU tauschen Frames direkt aus — der CPU kopiert nie Pixel-Daten. Führen Sie fünf gleichzeitige Modelle plus H.265-Encoding auf einem 10-TOPS-class-Gerät aus und behalten Sie CPU-Headroom für Ihre Anwendungslogik frei.
MOS4 AI Software Suite
Build, Runtime und Language — drei Säulen.
MOS4 AI Software Suite umfasst Build (AI Funnel) + Runtime (AI Vision, AI Language). AI Vision ist die Runtime für visuelle Intelligenz — Kamera zu NPU ohne CPU-Pixel-Kopien. AI Language ist die Runtime für Text-Intelligenz — LLM, RAG und Sprache auf dem Gerät.
Kernansprüche
Die Zahlen und Design-Invarianten.
Kamera-Erfassung
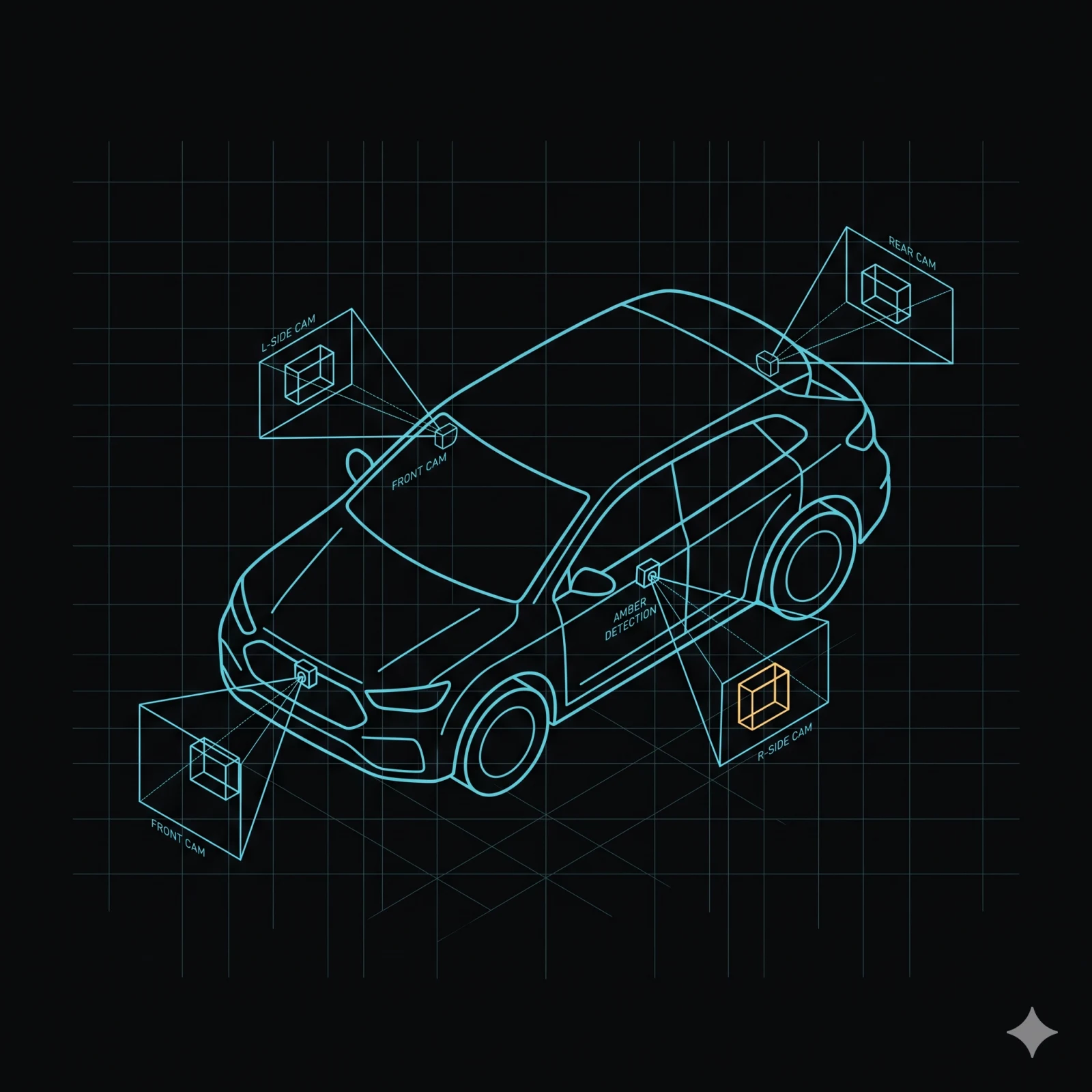
Fünf Kamera-Eingaben. Eine einheitliche API.
Fünf Kamera-Eingaben konvergieren auf demselben Shared-Memory-Frame-Format. Integratoren
schreiben keine pro-Plattform-Pipelines. Durchsuchen Sie den micro service-Katalog, um mos-camera-capture, mos-roi-shader und mos-ai-runtime zu erkunden.
Architektur
| Eingabe | Silizium-Backend | Hinweise |
|---|---|---|
| MIPI-CSI | AI-class / compute-class (direkt) | Natives MIPI-Interface; keine externe Bridge |
| GMSL2 | AI-class-Stufe (Vendor-Multimedia-Framework) | Serializer-Bridge-Pfad; MIPI-CSI direkt auf der anderen AI-class-Variante |
| USB UVC | Beide | Standard-V4L2-UVC-Klassentreiber |
| Ethernet RTSP/ONVIF | Beide | Netzwerk-Kameras; Live-RTSP-Streaming verfügbar |
| WebRTC | Beide | Browser-kompatibler Live-Streaming-Pfad |
Jedes Backend normalisiert die Ausgabe auf dasselbe Shared-GPU-Memory-Frame-Format vor dem Tee. Fünf Eingaben, ein Entry-Vertrag.
Kamera-zu-Verbraucher-Datenfluss. Der Sensor — MIPI-CSI, GMSL2, USB UVC, RTSP/ONVIF oder WebRTC — erzeugt Frames in gemeinsamen GPU-Speicher. Der Tee fächert den Frame dann ohne Kopieren auf drei Verbraucher auf: den GPU-ROI-Shader für Crop und Resize, den Dashcam-Encoder und den visuellen + inertialen Pose-Tracker. Der ROI-Shader übergibt Tensor-Handles an die KI-Laufzeit für NPU-Inferenz.
flowchart TD S[Kamera<br/>MIPI-CSI · GMSL2 · UVC · RTSP/ONVIF · WebRTC] S --> G[Gemeinsamer GPU-Speicher<br/>NV12-Frame] G --> T[Tee · Entry-Vertrag] T --> R[GPU-ROI-Shader<br/>Crop und Resize] T --> D[Dashcam-Encoder] T --> V[Pose-Tracker] R --> A[KI-Laufzeit<br/>NPU-Inferenz] class A ai-node class R ai-node
Skalierung + Dual-Mode + Wear
Ein bis acht Kameras ab Werk
Die Laufzeit unterstützt ein bis acht Kameras pro Gerät nativ über die fünf Transporte. Höhere Konfigurationen auf Anfrage.
Aufnahme + Stream + Upload gleichzeitig
Viele Kameraplattformen zwingen zur Wahl zwischen lokaler Aufnahme und Streaming oder Upload älterer Clips. MOS4 ist für beides gleichzeitig ausgelegt: Live-Encode in den flash-aware Segment-Sink, RTSP/WebRTC-Stream und Verlaufs-Clip-Upload laufen auf derselben Shared-Memory-Frame-Ebene, ohne Buffer-Duplikation.
Wear-Leveling-Speicher
Der Segment-Sink ist flash-aware: Schreibzugriffe werden über Blöcke rotiert, um die Lebensdauer auf Premium-SKUs mit Langzeitaufzeichnung zu verlängern. Aufbewahrungsrichtlinien, geschützte Clips und die Cloud-Upload-Queue teilen sich dieselbe Wear-Budget-Abrechnung.
Bringen Sie eine Kamera und ein Modell — wir routen die Pixel.
Frame-Transport
Ein Frame, viele Verbraucher — jeder in seinem eigenen Tempo.
Ein Frame erzeugt; viele Verbraucher abonnieren in unabhängigen Taktfolgen. Langsame Verbraucher blockieren nie den Produzenten; verworfene Frames werden pro Topic verfolgt.
bis zu 60 Hz
Video
Vollrate-Frames an den Dashcam-Encoder oder jeden Abonnenten — begrenzt auf 60 Hz. Siehe Video-Anwendungsfälle.
30 Hz
GPU-Crop und -Resize
ROI-Extraktion im NPU-Inferenz-Takt.
10 Hz
Pose-Tracking
Visuell + inertialer Pose-Tracker abonniert in seinem eigenen Takt — jeder Abonnent unabhängig.
Zweistufige Erkennung
Vollbild schnell scannen, dann auf relevante Bereiche erneut schauen.
Triage erkennt auf dem Vollbild; verfeinerte Modelle schauen dann nur auf die Regionen of Interest erneut. Die Metadaten-Schleife zwischen der KI-Laufzeit und dem GPU-Crop überträgt Bounding Boxes und eine Modell-ID — einige Bytes pro Erkennung, keine Pixel-Daten überqueren den Bus zwischen den Stufen.
Zweistufige Erkennung. Die Kamera veröffentlicht den Vollbild-Frame an die KI-Laufzeit, die Triage-Inferenz ausführt und Erkennungs-Bounding-Boxes mit Klassen-Labels und Konfidenz-Scores erzeugt. Die Laufzeit sendet dann Bounding-Box-Metadaten und eine Modell-ID — einige Bytes, keine Pixel-Daten — an den GPU-ROI-Shader. Der Shader croppt, resized und normalisiert jede Region und gibt ein Tensor-Handle pro ROI zurück. Die Laufzeit führt dann die verfeinerte Inferenz pro ROI aus.
sequenceDiagram participant Cam as Kamera participant Ai as KI-Laufzeit participant Roi as GPU-ROI-Shader Cam->>Ai: gemeinsamer Frame — Vollbild Note over Ai: Triage-Inferenz<br/>BBox + Klasse + Konfidenz erkennen Ai->>Roi: SelectRois(bbox[], model_id) — einige Bytes Note over Roi: GPU-Crop + Resize + Normalisieren pro ROI Roi-->>Ai: Tensor-Handle pro ROI (1:N) Note over Ai: Verfeinerte Inferenz pro ROI
GPU-Crop und -Resize
Gleiche Konfiguration, gleiche Schnittstelle — über Silizium-Familien hinweg.
Der GPU-ROI-Shader führt Crop, Resize und Normalisieren vollständig auf der GPU aus. Das Framework passt sich intern an die Hardware an — Integratoren sehen eine Konfiguration und eine Schnittstelle über Silizium-Familien hinweg. Die Metadaten-Schleife überträgt nur Bounding-Box und Modell-ID — keine Pixel.
Architektur · pro Silizium-Familie
AI-class — MIPI-CSI-Variante
GPU-ROI portabel. NPU-Inferenz über den Silicon-Vendor-Delegate. Direkter GPU-zu-NPU-Shared-Memory ist auf dieser Variante nicht verfügbar; der GPU-Ausgabe-Tensor wird als Standard-Tensor an den NPU übergeben.
AI-class — Serializer-Bridge-Variante
GPU-ROI portabel, plus GPU-zu-NPU-Shared-Memory für Tensor-Wiederverwendung ohne Reimport. Unterstützt bis zu ~100 TOPS auf der AI-class-Stufe.
Siehe unterstützte Hardware für Silizium-Stufen-Details und Formfaktoren.
NPU-Inferenz
KI-Laufzeit: Modelle nach Pfad oder Bytes laden.
Mehrere Modelle laden, gleichzeitig ausführen, ONNX oder TFLite direkt deployen. Same-Model-Re-Entry wird konstruktionsbedingt verhindert.
API-Oberfläche
| Methode | Beschreibung |
|---|---|
| LoadModel | Ein .tflite-Modell nach Pfad oder Bytes laden |
| UnloadModel | Ein Modell und seine NPU-Ressourcen freigeben |
| RunInference | Einen Shared-GPU-Memory-Frame als Eingabe akzeptieren; gibt Erkennungs-Tensoren zurück |
| ListModels | Geladene Modelle mit Metadaten aufzählen |
Mehrere Modelle laden und laufen gleichzeitig; Same-Model-Re-Entry ist konstruktionsbedingt unmöglich. Eingabe ist ausschließlich der Shared-GPU-Memory-Frame — kein CPU-Pixel-Copy-Pfad existiert in Produktionscode. ONNX-Modelle können vor dem Deployment auto-konvertiert werden.
Für den KI-Pipeline-Engine, DAG-Scheduling und Cloud-Connect-Integration, siehe AI Funnel.
Visuell + inertiales Pose-Tracking
Visuell + inertial + GNSS, on-device fusioniert.
Zukünftige Platzierung: Visuelle und inertiale Odometrie-Inhalte werden in einem zukünftigen Release auf eine dedizierte /platform/robotics-Seite verschoben. Bis diese Seite existiert, bleibt dieser Inhalt hier.
Pose-Tracking fusioniert Kamera, Inertial und GNSS. GNSS-Abwesenheit in Innenräumen triggert einen graceful Soft-Fail; Karten-Persistenz überlebt Neustarts.
Der ≤33-ms-Pro-Frame-Wert stammt aus einem synthetischen 300-Frame-Harness — kein validierter Echtzeit-Benchmark. Echtzeit-Timing ist ausstehend. Das Feature entsprechend kommunizieren.
Architektur
Das visuelle Frontend extrahiert Eck-Features, berechnet binäre Deskriptoren und bootstrapped Tracking mit robuster Ausreißer-Ablehnung. Inertiale Daten werden mit vollständiger Kovarianz vor-integriert; GNSS-Fusion läuft über einen Faktor-Graph-Optimierer. Keine externe SLAM-Bibliotheks-Abhängigkeit.
| Methode | Beschreibung |
|---|---|
| StreamPose | 6-DOF-Pose mit Kovarianz — rein visuell oder visuell-inertiale Fusion |
| GetStatus | Aktueller Pose-Tracker-Zustand und Tracking-Status |
| GetMapStats | Landmark-Anzahl, Keyframe-Anzahl, Loop-Closure-Anzahl |
| SaveMap | Aktuelle Karte für Neustart-Persistenz speichern |
| LoadMap | Gespeicherte Karte zum Bootstrap-Tracking wiederherstellen |
Karten-Persistenz überlebt Neustarts via atomaren Datei-Schreibvorgang.
DSGVO-Anonymisierung
Live-Anonymisierung, bevor ein Frame die Pipeline verlässt.
Eine optionale Anonymisierungsstufe läuft in der Capture-Pipeline — vor dem Dashcam-Encoder und vor jedem nachgelagerten Verbraucher. Nachgelagerte Services erhalten bereits anonymisierte Frames ohne zusätzlichen Integrationsschritt.
Was anonymisiert wird
Gesichter und Kennzeichen werden in der Pipeline pixeliert. Keine biometrischen Rohdaten erreichen den Encoder oder einen nachgelagerten Service.
Pipeline-Platzierung
Die Anonymisierungsstufe sitzt vor dem Dashcam-Encoder und vor allen anderen Frame-Verbrauchern. Es gibt keinen Nachverarbeitungsschritt und keine Notwendigkeit, über Services hinweg zu koordinieren.
Boot-Zeit-Richtlinie
Aktiviert oder deaktiviert über ein Boot-Zeit-Konfigurations-Flag. Live-Umschalten ohne Neustart wird nicht unterstützt — die Pipeline wird beim Start neu aufgebaut. Dies hält die Richtlinien-Durchsetzung auditierbar und deterministisch.
Dashcam-Integration
Der Dashcam-Encoder empfängt Frames, die bereits anonymisiert sind. Kein zusätzlicher Integrationsschritt erforderlich. Derselbe bereits anonymisierte Frame erreicht jeden anderen Abonnenten auf der Pipeline.
Observability
14 eingebaute Metriken über die Pipeline.
GPU-ROI-Shader — 6 Metriken
Aufrufe, extrahierte ROIs, Dauer-Histogramm und 3 weitere. Integriert sich in die MOS4-Observability-Pipeline ohne Pro-Service-Instrumentierungs-Code.
KI-Laufzeit — 8 Metriken
Counter, Histogramme und ein Gauge — inklusive eines Inferenz-Heartbeat-Watchdogs mit 5-s-Budget. Gleiche Zero-Instrumentation-Integration.
FAQ
Häufig gestellte Fragen
-
Welche Kamera-Eingaben werden unterstützt?
Fünf: MIPI-CSI (direkt auf AI-class / compute-class-Silizium), GMSL2 (AI-class-Serializer-Bridge-Pfad), USB UVC, Ethernet RTSP/ONVIF und WebRTC. Live-RTSP- und WebRTC-Streaming-Pfade sind beide verfügbar.
-
Berührt der CPU je Pixel-Daten?
Nein, absichtlich nicht. Kamera, GPU und NPU tauschen denselben Shared-Memory-Frame per Handle-Passing aus. CPU-Pixel-Mapping ist eine Spezifikationsverletzung in Produktions-Builds.
-
Kann ich mehrere KI-Modelle gleichzeitig mit Video-Encoding ausführen?
Ja. Die Pipeline ist darauf ausgelegt, eine vollständige DMS + ADAS-Arbeitslast (5 Modelle) plus H.265-Encoding auf einem 10-TOPS-class-Gerät mit freiem CPU-Headroom für Anwendungslogik auszuführen.
-
Wie integriert sich die DSGVO-Anonymisierung?
Eine optionale Anonymisierungsstufe pixeliert Gesichter und Kennzeichen, bevor Frames den Dashcam-Encoder oder andere nachgelagerte Verbraucher erreichen. Aktivieren oder Deaktivieren erfordert einen Neustart. Nachgelagerte Verbraucher erhalten bereits anonymisierte Frames ohne zusätzlichen Integrationsschritt.
-
Was bedeutet der Pose-Tracking-Timing-Wert?
Der ≤33-ms-Pro-Frame-Wert stammt aus einem synthetischen 300-Frame-Harness, kein validierter Echtzeit-Benchmark. Echtzeit-Benchmarking ist in Arbeit. Die Pipeline zielt auf 30 FPS.
Architektur-FAQ
Implementierungsdetails
-
Wie funktioniert ROI-Extraktion über Silizium-Familien hinweg?
Der GPU-ROI-Shader importiert den gemeinsamen GPU-Memory-Frame, führt Letterbox + Format-Konvertierung auf der GPU aus und gibt ein Tensor-Handle pro ROI aus. Der Shader ist über beide AI-class-Silizium-Varianten portabel. Eine AI-class-Variante unterstützt zusätzlich direkten GPU-zu-NPU-Shared-Memory, sodass der NPU den Tensor ohne Reimport wiederverwendet — dieser Pfad ist silizium-spezifisch.
-
Wie sieht die Pose-Tracking-Pipeline intern aus?
Das visuelle Frontend extrahiert Eck-Features, berechnet binäre Deskriptoren und bootstrapped Tracking mit robuster Ausreißer-Ablehnung. Inertiale Daten werden mit vollständiger Kovarianz vor-integriert und mit GNSS über einen Faktor-Graph-Optimierer fusioniert. Keine externe SLAM-Bibliotheks-Abhängigkeit — die gesamte Pipeline ist in Rust geschrieben.
Bringen Sie eine Kamera und einen Use-Case.
Eine Live-Demo auf Munic-Hardware — in Ihrem Büro, Ihrem Fahrzeug oder Ihrer Maschine. Mit dem Engineering-Team sprechen, um die SoC-Stufe an Ihr Latenz- und Rechenbudget anzupassen.